本文共 3057 字,大约阅读时间需要 10 分钟。
为了加速自然语言处理(NLP)在更多语言上进行零样本迁移,Facebook 扩展并增强了LASER(Language-Agnostic SEntence Representations)工具包,并将其开源。这是第一个成功探索大型多语种句子表示并与广大NLP社区共享的工具。
该工具包现在可以使用90多种语言和28种不同的字母表。LASER通过将所有语言联合嵌入到单个共享空间(而不是为每种语言分别建立单独的模型)来实现这些结果。我们现在免费提供多语言编码器和,以及针对100多种语言的多语言测试集。
LASER打开了从一种语言(如英语)到其他几种语言(包括训练数据极为有限的语言)进行NLP模型零样本迁移的大门。LASER是第一个使用单一模型处理各种语言的库,包括低资源语言(如卡拜尔语和维吾尔语),以及中国的吴语等方言。有朝一日,这项工作可以帮助Facebook和其他公司推出一些特定的NLP功能,例如,使用一种语言将电影评论分类为正面或负面,然后再使用其他100多种语言发布。
性能和功能亮点
LASER为XNLI语料库14种语言中的13种带来了更高的零样本跨语言自然语言推理准确率。它还在跨语言文档分类(MLDoc语料库)方面获得了很好的结果。我们的句子嵌入在并行语料库挖掘方面也有很好的表现,在BUCC(BUCC是在2018年举行的一个构建和使用可比较语料库研讨会)共享任务中将四个语言对中的三个提升到了一个新的技术水平。除了LASER工具包,我们在Tatoeba语料库的基础上共享了100多种语言对齐句子的测试集。使用这个数据集,我们的句子嵌入在多语言相似性搜索中获得了很好的结果,即使是低资源语言也是如此。
LASER还提供了其他的一些好处:
- 它提供了极快的性能,在GPU上每秒处理多达2,000个句子。
- 句子编码器使用PyTorch实现,只有很少的外部依赖。
- 低资源语言可以从多种语言的联合训练中受益。
- 该模型支持在一个句子中使用多种语言。
- 随着新语言的添加,性能会有所提高,因为系统会学会识别语言族的特征。
通用的语言无关性句子嵌入
LASER的句子向量表示对于输入语言和NLP任务都是通用的。它将语言的句子映射到高维空间中的一个点,目标是让语言中的相同语句最终出现在同一邻域中。该表示可以被视为语义向量空间中的一种通用语言。我们已经观察到,空间中的距离与句子的语义紧密程度密切相关。
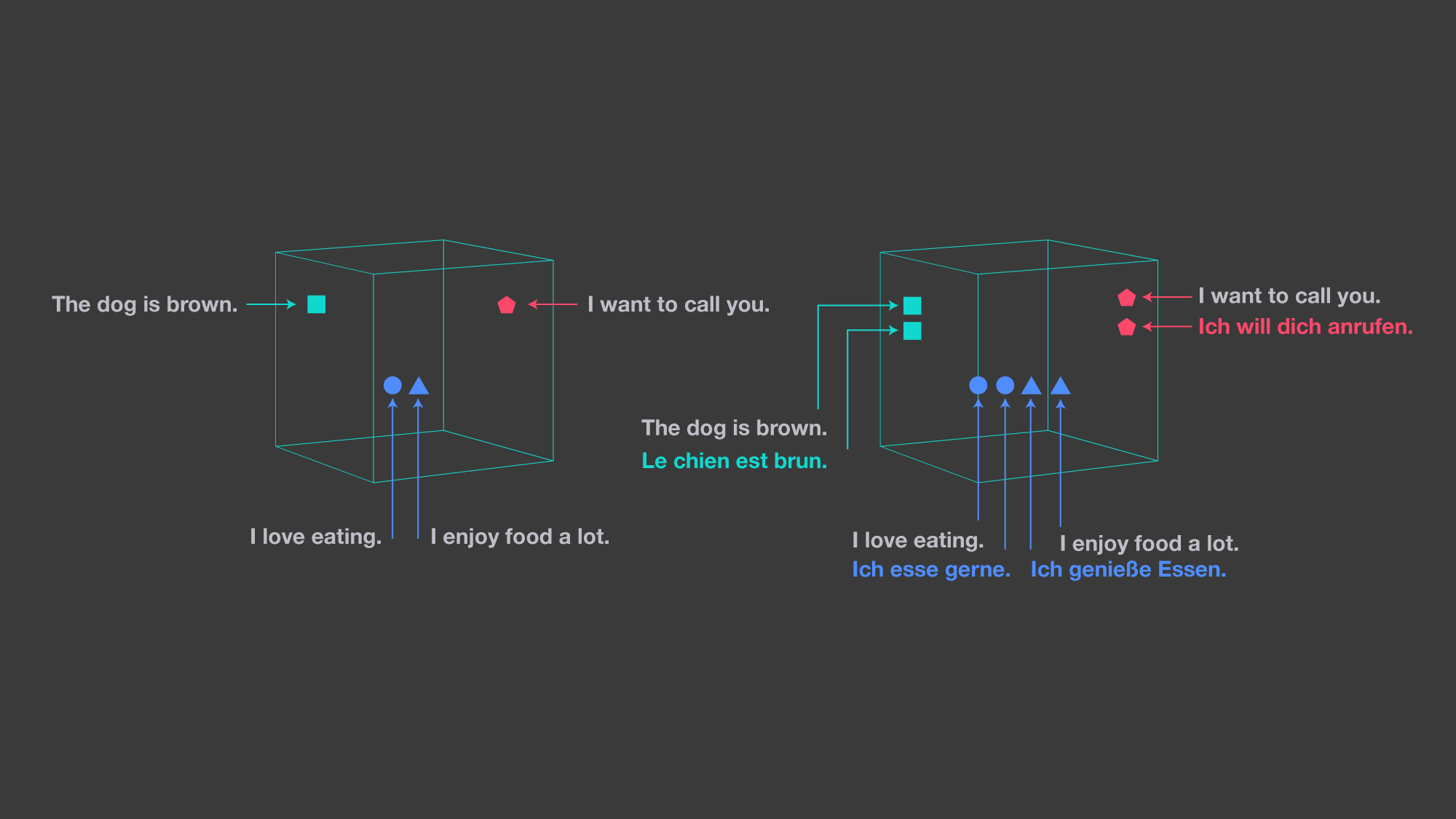
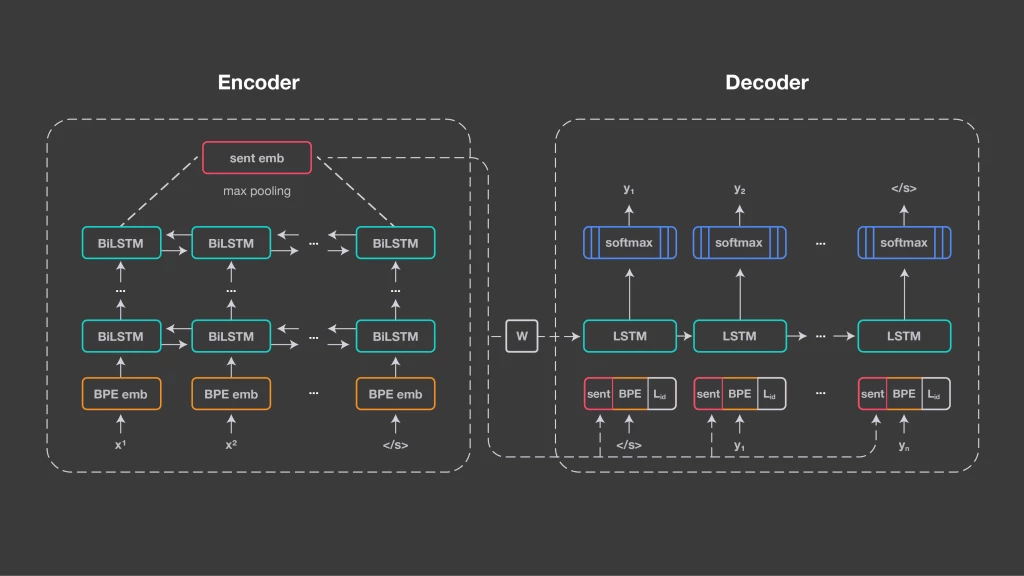
我们必须告诉解码器要生成哪种语言。它需要一个语言标识,也就是在每个时间步骤上连接到输入和句子嵌入的标识。我们使用具有50,000个操作的联合字节对编码(BPE)词汇表,在所有连接的训练语料库上进行训练。由于编码器没有指示输入语言的显式信号,因此编码器需要学习与语言无关的表示。我们基于公共并行数据的2.23亿个句子(它们与英语或西班牙语对齐)训练我们的系统。对于每个迷你批次,我们随机选择一种输入语言,让系统将句子翻译成英语或西班牙语。大多数语言都与目标语言保持一致,虽然这不是必需的。
我们刚开始训练了不到10种欧洲语言,所有语言都使用了相同的拉丁文字。后来,我们逐渐增加到Europarl语料库中提供的21种语言,结果表明,随着我们添加的语言越来越多,多语言迁移性能也得到了提升。系统学习了语言家族的通用特征。通过这种方式,低资源语言可以从同一族高资源语言的资源中获益。
这可能可以通过使用在所有语言的连接上训练的共享BPE词汇表来实现。我们对每种语言BPE词汇表分布之间的对称Kullback-Leiber距离进行了分析和聚类,结果显示,Kullback-Leiber距离与语言家族具有几乎完美的相关性。


零样本跨语言的自然语言推理
我们的模型在跨语言自然语言推理(NLI)中获得了良好的效果。在这项任务上的表现是一个强有力的指标,它能够很好地说明这个模型是如何表达一个句子的意思的。我们针对英语训练NLI分类器,然后将其应用于所有目标语言,不需要进行微调或使用目标语言资源。在14种语言中,有8种语言的零样本性能表现在英语的5%以内,包括俄语、中文和越南语等。我们在斯瓦希里语和乌尔都语等低资源语言上也取得了很好的成绩。最后,LASER在14种语言中的13种语言上的表现优于所有以前的零样本迁移方法。
与之前的方法不同,之前的方法需要一个英语句子,而我们的系统是完全多语言的,并且支持不同语言的任意前提和假设组合。
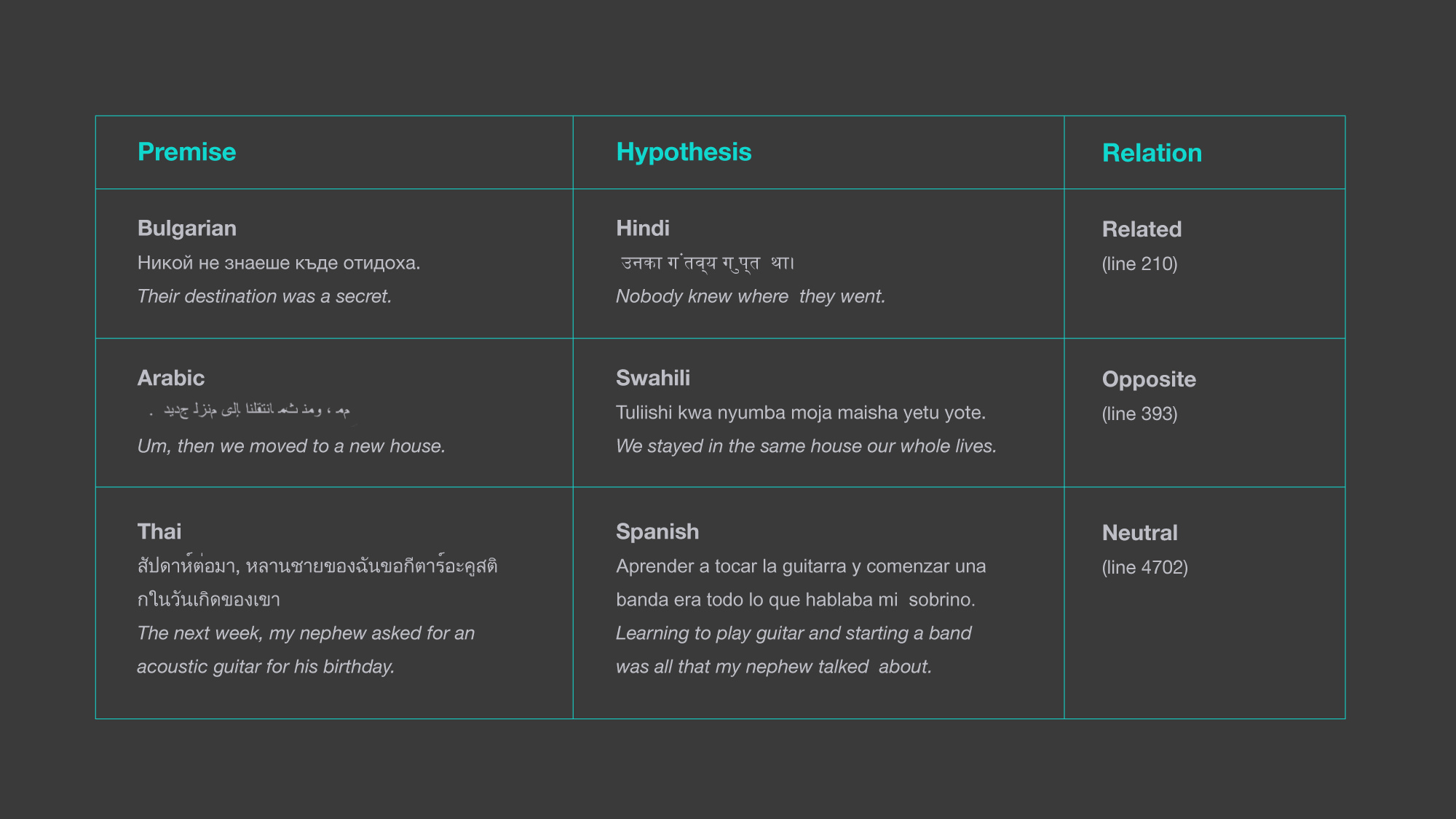
我们在共享BUCC任务上的表现远远超过了现有水平。我们的系统明显是为完成这个任务而开发的。我们将德语/英语的F1得分从85.5提高到96.2,法语/英语从81.5提高到93.9,俄语/英语从81.3提高到93.3,汉语/英语从77.5提高到92.3。正如这些示例所示,我们的结果在所有语言中都是高度同质的。
该方法的详细信息可以在这篇研究论文中找到:。
同样的方法也适用于使用任意语言对在90多种语言中挖掘并行数据。预计这将显著改善许多依赖于并行训练数据的NLP应用程序,包括低资源语言的神经机器翻译。
未来的应用
LASER还可以用于其他相关任务。例如,多语言语义空间特性可用于解释一个句子或搜索具有类似含义的句子——可以使用相同的语言,也可以使用LASER目前支持的93种其他语言中的任意一种。我们将继续改进我们的模型,在现有的93种语言基础上增加更多的语言。
英文原文:
转载地址:http://nqjbx.baihongyu.com/